摘要:識别(identification)是在理論假定基礎上将實證信息與研究對象進行獨一無二的映射,是社會科學實證研究的基本任務和核心工作。社會科學正經曆着兩大變革,即數據革命(the Data Revolution)和識别革命(the Identification Revolution)。在數據革命似乎變一切“不可能”為“可能”時,識别革命卻懷疑這些“可能性”的信度(credibility),诘問研究“變為可能”的代價,強調理論假定的清晰度(cleanness)和透明度(transparency),要求建立嚴格信度标準下的“設計驅動型”實證研究範式。在識别革命尚待推進的一些領域,大數據帶來機遇的同時也伴随着研究缺乏信度、理論與實證脫節、過度量化等問題的凸顯。強化識别意識和識别策略設計,提高實證研究的信度、連接理論和實證并恰當适度地使用數據及技術,對于大數據時代的社會科學發展具有迫切而深遠的意義。
關鍵詞:識别革命 信度 設計驅動型研究 大數據 經驗主義
作者龐珣,beat365國際關系學系教授(北京100084)。
責任編輯:張萍 褚國飛
來源:《中國社會科學評價》2021年第3期P62—P71
當前社會科學研究正經曆着數據革命和識别革命(又稱“信度革命”)兩大變革。它們都已持續多年并從根本上改變着研究的範式和形式。數據革命在近年來尤其高歌猛進,呈排山倒海之勢。海量、多樣和實時的數據在井噴式的新算法技術助力下,極大拓展了社會科學的研究議題和探索空間。相比而言,識别革命更像是“靜悄悄的革命”,但在其持續約四十年的時間裡已經證明了它持久的生命力和創新性。識别革命要求對數據和技術采取前所未有的謹慎态度,強調以嚴格的研究設計來提高實證研究的信度,堅守科學内核而拒絕經驗主義。在數據革命似乎把一切不可能變為可能時,識别革命卻懷疑這些“可能”的信度,要求诘問研究“變為可能”的代價。識别革命在某種意義上是反機械化、反自動化和反技術流的,而數據革命則以将一切工作交予機器為評判進步的标準。如此,數據革命和識别革命形成了一個“雙重運動”。數據革命以“技術”來強勢擴展自己的邊界,而識别革命則以捍衛研究的科學“價值”(信度)為使命,要将數據革命限制在某個合理的範圍内以抵禦經驗主義的誘惑。已有實踐表明,平衡數據革命與識别革命的“雙重運動”,對社會科學健康蓬勃發展至為關鍵。但在識别革命尚未确立地位的一些領域中,當數據革命的浪潮席卷而來時,令人擔憂的問題和有識之士的焦慮也随之加深。
例如,海量數據、前沿技術和強大計算能力貌似銅牆鐵壁地保證着實證發現的信度,但令人眼花缭亂的“數據技術密集型”實證研究得出的結論卻常常顯得“不靠譜”。是什麼的缺失造成了數據技術與研究信度之間的緊張關系?理論與實證脫節的情況依然嚴峻,大數據與計算社會科學等新興研究範式的發展不僅沒有起到彌合作用,反而在加速兩者之間的脫節。理論與實證脫節的症結究竟在哪裡?是否不可避免?數據革命帶來了對社會科學“過度量化”的批評和擔憂。數據及其分析技術在什麼意義上被“過度”使用了?“過度”中的“度”在哪裡?過度使用在什麼意義上損害到社會科學?
以上問題的出現可以視為數據革命趨向“脫嵌”于研究的科學内核的表現。識别革命通過拒絕經驗主義而對這種趨勢進行回推,對于保證數據革命的“嵌入”——服務于追求持久性知識而非滿足于對經驗現象的追逐——十分必要。缺乏識别革命回推絕非數據革命的完勝,如果深切的焦慮得不到回應、嚴重的問題得不到解決,社會科學中的一些領域也可能放棄數據革命帶來的機遇作為保護社會科學精神内核的代價。
為什麼識别革命是在大數據時代保障研究信度、防止理論與實證脫節、避免過度量化的關鍵?圍繞識别進行的“設計驅動型研究”(design-driven 或design-based research)如何區别于傳統的“模型驅動型研究”(model-driven research) 和當前盛行的“數據驅動型研究”(data-driven research)?本文将對這些問題進行抛磚引玉的讨論,目的不在于全面系統地介紹識别革命或識别策略,而是聚焦于設計驅動型研究範式對于社會科學的重要性和緊迫性,探讨社會科學如何恰當而充分地受益于數據革命帶來的機遇。數據革命和識别革命之間可以,并也已經在一些領域内建立起互補互助、相得益彰的關系,但基于本文的關切所在,讨論的重心将集中于當前研究實踐中呈現出的兩者之間的張力(tension),偏重強調識别革命而非數據革命在平衡“雙重運動”中的作用。
一、避免錯誤的實證結果:識别意識與研究信度
識别可以被簡單地定義為,在理論假定基礎上将實證信息與研究對象(quantity of interest)進行獨一無二的映射。這裡的研究對象通常是難以直接觀測的、具有理論意義的存在及其相互關系,本文統稱為識别對象。識别任務是要尋找和認證識别對象或其局部的經驗呈現,從而連接和貫通理論世界和經驗世界。這裡的“識别”不同于今天家喻戶曉的大數據人工智能語境下的“識别”,也不限于狹義的因果識别,更不是定量研究的特有任務。相反,識别是所有類型實證社會科學中基本和核心的工作,貫穿于測量、描述、因果探索以及預測等各個方面。
識别關乎我們在理論假定和實證信息的基礎上可以(或不可以)得出什麼結論的問題,因此“識别革命”又稱為“信度革命”,即以專注識别問題來提高研究信度。 信度問題區别于學術誠信,它不是學術倫理問題,而是研究質量問題。如果研究者對識别對象及其可識别性(identifiability)的判斷出現偏差、沒有對理論假定進行認真思考和明确探讨、或對識别所需(所缺)信息思慮不周或決策不當,就會得到偏差或錯誤的實證結果、下不該下的結論。保證信度的首要條件不是增大數據量或升級計算技術,而是強化識别意識和嚴謹化識别策略。由于缺乏自覺的識别意識而出現信度問題的研究比比皆是。我們可以通過一個看似安全但卻“翻車”的真實研究例子,一窺識别的無處不在以及識别錯誤如何導緻研究“下不該下的結論”。
政治學知名學術期刊在2003年發表一篇研究論文,探讨自殺性恐怖襲擊現象背後的理性邏輯。研究報告了一個重要的實證發現,即自殺性恐怖襲擊的發生與西方國家在相關恐怖主義組織所認為的本國領土上駐軍(簡稱“軍事占領”)高度正相關,暗示軍事占領可能是導緻自殺性恐怖襲擊的原因,并提出了停止以軍事占領來打擊和遏制恐怖主義活動的政策建議。這一結論所建立的實證信息來自作者對全球新聞在線數據庫進行的全面提取,得到了1980年到2001年間所有公開可知的188件自殺性恐襲事件。從數據量和人工編碼方式來看,論文并非“大數據”研究,但從文本數據庫獲取事件數據是國際關系中大數據研究的重要思路和長期探索,因此這一原創性數據集被認為是該研究的最大亮點之一。作者通過描述性分析發現,在這188件自殺性恐襲事件中,涉及軍事占領的事件有178件,約占94.68%,并在這個百分比的基礎上得出以上結論。94.68%這個比例、作者獲取數據的途徑、數據公開透明的态度和規範,都讓這個研究發現看上去具有很高的可信度。時值“9·11”事件發生後不久和美國發動伊拉克戰争伊始,該文的這一實證發現在當時也産生了廣泛的政治社會影響。
然而時隔5年後,另外四位學者在同一期刊上發表聯合署名文章,從識别的角度分析和指出了前文作者的實證結論因存在重大錯誤而完全缺乏信度。批評者認為,這些數據不但無法用于識别自殺性恐襲與軍事占領之間的相關性,而且即使僅對這一相關性的可能範圍進行識别,這些數據也幾乎毫無價值。值得注意的是,批評者們并沒有以“相關不等于因果”來苛責這個研究,這更凸顯了信度問題并非獨屬因果研究(推論)的問題。他們将識别對象限制在相關關系上并正式而清晰地表達為:
識别對象=Pr(Suicide|Occupation)-Pr(Suicide|~Occupation)(1)
第一個條件概率是軍事占領的情況下(Occupation)發生自殺性襲擊(Suicide)的概率,第二個是沒有軍事占領的情況下(~Occupation)自殺性襲擊概率,兩者的差異顯示軍事占領是否與更高的自殺性襲擊風險相關。在明确了識别對象後,我們就可以來看識别這個對象要求什麼樣的實證信息。将式(1)作一個簡單的概率變換得到:
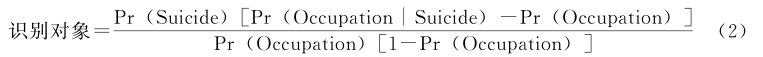
根據式(2),要識别這一相關關系我們需要關于構成該識别對象的三個概率的信息,即Pr(Suicide) 、Pr(Occupation|Suicide) 和Pr(Occupation)。原文透露了第一個概率的實證信息:4155件恐怖襲擊中有188件自殺性恐怖襲擊,因此PrSuicide≈4.52%。研究中也包含關于第二個概率的信息,Pr(Occupation|Suicide) ≈94.68%。但原文作者沒有搜集第三個概率PrOccupation的信息。這表明,原文的實證信息根本無法得出軍事占領和自殺性恐怖襲擊之間的高度正相關的結論,但原作者卻将這個結論建立在其中一個組成概率的實證信息上,誤将Pr(Occupation|Suicide) ≈94.68%當作識别結果,基于這一錯誤的識别結果下結論和給建議。
批評者們繼續放松對識别對象的要求,不求對相關關系進行“點識别”(精确到對象本身),而是看數據能在多大程度上局部識别相關關系的邊界和範圍。他們根據原文提供的信息對這個信息缺失的概率進行邊界值估算,得到178/4145≤PrOccupation≤4145/4145, 即4145件恐怖襲擊事件中至少已知178件有軍事占領情況。将這兩個邊界值帶入式(2)可以計算出-0.957≤識别對象≤0.944。但即使沒有任何關于這個識别對象的信息,我們也知道-1≤識别對象≤1,因為兩個概率相減不可能小于-1或大于1。比較兩組邊界值不難看出,原作者的數據對我們關于研究對象的知識促進微乎其微。
至此,從方法論的角度我們已經看出這是一個典型的“根據因變量進行選擇”錯誤,盡管“因變量”一詞在這一相關關系研究中并不準确。從識别的角度來理解,我們不但可以更清楚地看到這是一個識别對象定義不清引起的錯誤,而且能夠體會到錯誤背後的原因是識别意識的缺乏或薄弱。原作者或許僅将識别等同于因果識别,而認為相關關系、描述或測量研究無關乎識别,從而無須進行識别的嚴謹思考和設計。但事實是,隻要不隻是就信息談信息、就判斷談判斷,而是将信息和判斷相連即構成識别。此外,這個例子表明,信度問題并非定量研究中才會出現的問題,因為該研究從嚴格意義上說是一個定性研究(描述性而非推論性研究),這個錯誤尤其發人深省。
本文用這個簡單的例子來強調“識别意識”是保證研究信度的前提,它也顯示了研究信度出現問題與識别難度并無必然關系。事實上,并不存在“識别難度高則研究信度低”這樣的邏輯和規律。例子中識别對象的識别難度可謂很低,而且所犯的錯誤在數據革命時代極易改正和彌補——我們可以立即搜集所需要的數據來估算Pr(Occupation)。但這并不表明錯誤本身無足輕重,更不意味着錯誤容易被發現或避免。其實,正是因為此類錯誤的普遍性,我們才需要強調要以嚴謹的識别設計來避免識别錯誤對研究信度的傷害。保證實證研究信度的關鍵是研究設計而不是數據量或分析技術。在識别策略正确的前提下,數據和技術可以提高識别的精确度和降低不确定性,但識别設計的錯誤則很難通過增大數據和技術複雜程度來自動糾正。原文“亮點之一”的原創性數據對識别幾乎毫無用處,告訴我們數據是否“有用”不在于其本身的新穎性、原創性、甚至是質量高低或規模大小,而是取決于它是否以及在多大程度上能夠服務于特定的研究任務。我們可以進一步想象,原作者使用最先進的方法對事件進行機器編碼而得到關于自殺性襲擊的“全樣本”,可以極大提高對Pr(Occupation|Suicide)這個概率估計的精度,卻仍然無助于識别軍事占領與自殺性恐怖襲擊之間的相關關系,也無法提升研究信度。
二、避免理論與實證的脫節:定位和定義識别對象
對理論與實證脫節的擔憂至少有兩層不同的意思:一是兩者在發展節奏上的差異越來越大,理論研究創新突破緩慢而實證研究在數據和技術的推動下日新月異;二是兩者有相背而行的趨勢,實證研究在數據革命中趨向經驗主義,而理論研究則從定義和本質上拒絕經驗主義。兩者漸行漸遠不利于任何一方:實證研究趨向經驗主義而缺乏對持久知識的追求,而理論研究不結合實證檢驗則隻能止于猜想和思辨。社會科學理論的構建方式在公理、數理或正式邏輯方面通常相對薄弱,實證就成為檢驗理論的主要甚至是唯一的途徑。避免理論與實證的脫節,需要雙方調整節奏、付出努力,相向而行并在“識别”處相遇。
識别如何讓實證研究向理論而行?模型驅動型研究對于識别對象的選擇、定義和認識太過依賴方法設定和工作慣性,而數據驅動型研究則偏重缺乏理論關懷的識别對象,兩者都不利于實證與理論的結合。設計驅動型研究要求将識别對象的定位、定義和表達作為識别策略設計的關鍵環節、先于和高于數據搜集和方法選擇。我們以一個假想的例子來比較模型驅動型研究和設計驅動型研究在定位和定義識别對象時的不同做法,并分析由此産生的實證分析與理論之間距離的差别。
模型驅動型研究确定識别對象的方式是以建立一個回歸模型為暗含的思路和要求,我們說的“因變量”其實就是模型等式左端的量,而“自變量”是右端的量,确定了這兩個變量即可以建立一個回歸模型。于是,“有清晰的因變量和自變量”成為模型驅動型實證研究确立識别對象的路徑。現在設想我們要研究關貿總協定/世界貿易組織(GATT/WTO)對國家出口帶來的影響,根據模型驅動型研究的做法,我們知道 “自變量”為GATT/WTO,操作化為“是否為GATT/WTO成員國”,而因變量為一國的出口量。識别對象就這樣确立為下式中的β1:
yit=f(β1xit,αzit)+εit(3)
式中腳标i和t分别表示“國家”“年份”,yit是自變量(國家的出口總量),而xit是因變量(是否為GATT/WTO成員國的啞變量),zit是以α為系數的控制變量,εit是殘差項,f(.)是某種模型的方程形狀(線性或非線性,更嚴格的寫法為g-1(.))。自變量xit的系數β1即是這個模型表達出來的“識别對象”,解讀為“其他條件不變(或其他變量固定在某個特定取值),一國從非GATT/WTO成員國變為成員國帶來其當年出口變化期望值為β1”,即GATT/WTO對出口的因果效應。這個流程簡單流暢,充滿程式化色彩,像一個有質量保證的成熟生産線。
然而,設計驅動型研究則要求在定位和定義識别對象時不可“輕舉妄動”,認為“因變量—自變量”方式定義的識别對象依然過于模糊。我們必須通過思考一系列理論和邏輯問題來謹慎地、清晰地确定識别對象,如:我們關心的“因”究竟是什麼?是成員國身份的轉變、是轉變的時機、還是GATT/WTO形成的網絡帶來的結構性影響?等等。對這些問題的回答取決于對國際組織的何種理論關切,是關心它帶來的外部機遇、對國内政策共識的促進或它形成的國家間同侪壓力?我們選擇原因的不同變化維度其實就是在構建不同的理論。進而,我們還需思考,理論關心對“誰”在什麼時段内的結果的影響?關心所有各具特色的國家還是某類經濟體?關心所有時間還是某個特殊時段?對這些問題的不同回答将定義出不同的識别對象。設計驅動型研究将定位和定義實證識别對象和理論構建融為一體,而不是将理論和實證人為割裂為兩個不同的階段。最重要的是,确定識别對象的過程與模型和數據無關,而是探究識别任務的理論意義和邏輯可能性,即設計必須先于實證觀察和實證分析。選擇和定義識别對象要求思考的廣度和深度遠超出慣常所講的“問一個清晰的研究問題”或确定“因變量和自變量”。
設計驅動型研究還要求研究者将識别對象盡量正式地表達出來,然後再根據需要選擇數據和實證方法,而不是根據數據和模型來表達識别對象,這一先後次序十分關鍵、不能颠倒。對識别對象的表達可以使用語言文字或數學符号,但須清晰而精确。回到GATT/WTO的例子,設計驅動型研究不會将識别對象表達為某統計模型中的系數,因為此時統計模型還未進入研究者的考量範圍中,是否使用任何統計模型則要在之後根據識别任務的要求來決定。我們這個假想的例子涉及因果關系為識别對象,研究者可以選擇“魯賓因果模型”(Neyman-Rubin Potential Outcomes)對因果效應的表達方式:

其中,δit是i國在t年的因果效應(由原因帶來的出口量的改變),Yit 表示i國在t年的潛在出口量(結果),而括号裡面的字母分别表示對不同類型原因的考慮:wit(i國t年是否為成員國)、 ai(i國何時加入GATT/WTO,a'i為另一個可能的年份)、Wt(所有國家在t年是否GATT/WTO的組合,W't是另一種可能的不同組合)。将識别對象正式表達出來的優勢,不僅在于明确了什麼是原因、因果效應是對哪兩種清晰定義的原因狀态對應的結果進行比較等必要問題,而且體現了真正的“其他條件不變”,即包括單元i和時間t的不變,與因果關系的理論相契合。這種表達還坦率承認了因果識别的巨大困難。我們如果仔細想一想就會發現,識别對象δit“無法識别”,因為對任何特定國家i在任何特定一年t,等式右邊的兩個結果最多隻有一個可以被實證觀察到(假設第一個是觀察到的事實),而另外一個則是永遠無法被實證觀察到的“反事實”。而在回歸表達中,我們掩蓋了這一“因果推論中的最基本難題”。現代因果識别研究正是在承認個體因果效應無法識别的基礎上,通過調整識别對象和明确識别假定,不斷将原來“不可識别”的對象變得“可識别”的科學探索。
從理論一方看,識别雖不是理論構建的必要工作,但帶着識别意識進行理論創新,對避免所創建的理論與實證脫節至關重要。這對理論創新本身有莫大裨益,因為如果理論無法在經驗世界中找到哪怕是局部的或間接的映射,這個理論就會由于缺乏實證檢驗而停留于猜想。或許有人擔心,顧及實證考量的可行性會限制“理論高度”,認為經驗世界由特殊性構成,因此理論的普遍性越高,它在現實中的可識别度就越低。這種擔憂是對實證研究的誤解,将其等同于直接觀察所得。實證研究盡管可以停留于經驗歸納,但更多的實證方法是推論性的,即超越經驗觀察而作為連接理論世界和經驗世界之間的橋梁。換言之,實證方法通常緻力于幫助我們從經驗世界的束縛中走出足夠遠而可以與純粹的理論在某處相彙合。普遍性高的理論并非不能通過實證研究來與現實世界相連接,關鍵在于理論對象的可識别性和實證研究的識别策略,即橋梁應架在哪裡和橋梁應如何設計。因此,不可識别在任何情況下都不應成為對理論的褒獎。
有一些理論的不可識别性确系觀測技術滞後所帶來,克服這類理論與實證相脫節問題需要後者的努力而非理論的屈就。但其他一些不可識别的理論則需要修改理論本身,如果不可識别性來自理論自身的缺陷,如概念含混和概念間邏輯關系模糊導緻無法定位識别對象、假定設置過強以緻完全無法映射到現實世界等。緻力于理論創新的研究者在構建自己的理論時,有必要考慮以下問題:理論哪些部分可識别、哪些部分無法識别?這些部分對整個理論而言在邏輯上處于什麼地位?可識别部分的主要識别困難在哪裡?不可識别部分能否進行修改而變得盡量可識别?理論有哪些可觀察含意(observable implications)?等等。帶着這些問題進行理論構建,不但能夠幫助理論得到實證檢驗,還有助于理論的嚴謹和優雅。
三、避免過度量化:明确和透明的識别假定
判斷任何現象和行為是否“過度”,首先需要明确什麼是“适度”以及在什麼意義上超過了這個合适的“度”。即使定量研究使用的頻度非常高、範圍非常廣和增長速度非常快(事實上在很多社會科學領域并非如此),其本身都不必然為“過度量化”。從識别的角度來理解過度量化的問題,“過度”可能是因為定量研究在以下三個方面産生了問題。第一,過度擴展定量研究的識别對象範疇,對那些在理論和邏輯上缺乏可識别性的對象進行強行(錯誤或有重大偏差的)識别。第二,将識别策略等同于對數據的技術分析,忽視或否認理論假定在識别策略中的重要作用和地位,缺乏對理論假定的深入探讨和仔細斟酌。第三,試圖以數據和技術來彌補甚至是自動糾正識别設計中的缺陷和錯誤。
“不可識别”并不是研究對象的“不可知”,而是對在什麼程度上“可知”的判斷錯誤。前文的探讨中我們已經看到,在選擇和定義識别對象時,設計驅動型研究承認不是所有的對象在任意程度上均可以得到識别,比如因果效應因包含無法觀測的“反事實”而不可“精準”識别,隻能進行近似識别。即使我們有再多的數據和再強的技術,也無法直接觀測到它。如果無視這一點而認為大數據可以提供因果識别的全樣本從而通過直接觀測而非推論即可識别因果效應,從而不承認識别所依賴的假定以及識别結果的不确定性,就會産生“過度量化”的問題。
任何識别對象的“可識别”均不同程度建立在識别假定上,數據的豐富和技術的進步可以幫助我們放松一些識别假定,但“可識别”始終無法做到完全脫離假定。因此,我們有必要讓這些假定清晰化和透明化,而用數據和技術來淹沒或掩蓋這些假定則會造成“過度量化”。比如,在上文的GATT/WTO例子中,雖然個體因果效應不可識别,但我們可以給予一個強假定,Yit(0) =Yjt(0) ,即非GATT/WTO國家j的出口結果可以視為GATT/WTO國家i在t年的“反事實”而提供所需識别信息。這之所以是一個假定而無法用數據或技術來證明或檢驗,仍在于它是對從定義上即無法觀測的反事實Yit(0)的假定。如果不願意使用如此強的假定,我們還可以通過降低識别對象細粒度來降低識别難度,“退而求其次”地追求平均因果效應δ=E[Y(1)-Y(0)\]。雖說從個體因果效應到平均因果效應還是沒有解決“反事實”不可觀測的問題,但假定一組“國家—年份”的平均結果為另一組的平均結果的反事實,這個假定要比在個體層次上更弱、更有可能成立。比如在随機實驗的條件下,随機分配讓“可忽略性”(ignorability)這一關鍵識别假定變得合理,一組單元的平均可以合理地視為另一組單元平均的反事實,從而δ成為可識别的對象。但社會科學能夠進行随機試驗的情況很少,大多時候隻能依靠觀察性信息,因此無法較好地滿足“可忽略性”假定。比如,我們很難接受國家加入或不加入GATT/WTO是随機選擇的假定,即“可忽略性”假定難以成立,從而δ仍然不可識别。于是,我們可能不得不繼續“退而求其次”定義一個新的可識别的對象,比如“條件的平均因果效應”δ(Z)=E[Y1-Y0 |Z\]。這個識别對象的“可識别性”建立在“有條件可忽略性”假定上,即隻要GATT/WTO成員國和非成員國在Z維度上的特征相同,我們就可以将它們的結果視為彼此的反事實。這些Z在設計驅動型研究中叫“混雜因子”(confounders),因為它們與結果之間的關系會混雜在我們感興趣的這對因果關系中。“有條件可忽略性”是否成立依然無法以數據和技術來進行檢測或保障,因為這一假定排除了Z之外的其他數不勝數的維度上的特征是混雜因子的可能,包括可觀測的和不可觀測的特征。我們隻能根據理論和邏輯來謹慎選擇Z,盡量讓這個假定“合理”。數據或計算技術可以在特定情況下對一些不可觀測的混雜因子進行近似,但仍然必須依靠假定來排除為數衆多的可能的混雜因子而使δ(Z)可識别。
如此依賴假定的識别,是否讓研究變得主觀而缺乏信度?回答是否定的。假定的使用無疑會讓研究的主觀性增大,但以正确的态度對待和處理假定卻恰恰是研究信度的保障。無論我們承認與否,所有的理論和實證研究都會在不同程度上依賴假定。沒有假定的研究,也正是非理論研究(atheoretical research)。我們并不能在“要假定”和“不要假定”之間做選擇,隻能選擇何種假定和如何假定,認真回答以下問題:哪些假定是必須的?哪些假定可以被放寬?哪些假定太強以至于我們甯可放棄識别對象也不願做出?在對同一個識别對象的不同識别策略中,我們偏好使用更少、更弱的假定而能夠得到同樣無偏和有效識别結果的設計。但識别研究一般始于較強的假定,随着知識和經驗的積累以及數據和方法的改進,一些假定逐漸得到放松。假定不是反科學而是科學的組成部分,假定清晰和透明正是科學精神的要求和科學工作的規範。既然假定構成了研究工作的重要部分,它就需要被報告,它的合理性和必要性就需要被公開讨論、質疑和挑戰。為了追求“客觀”表象而淡化甚至藏匿假定的态度與做法是反科學的。正是對假定的承認和讨論讓研究的可信度上升,而回避談論假定而制造客觀的假象,對社會科學研究的信度造成傷害。
避免過度量化除了将識别假定提到重要位置,還要求對數據及其分析技術采取正确的态度。它們是實證研究完成識别任務的必須,信息的豐富和技術的進步也能夠幫助我們放松一些識别假定和降低識别的不确定性。但是,數據和技術無法彌補識别策略在設計上的根本缺陷,如錯誤定義或模糊不清的識别對象、無意識下所依賴的不合理的假定等。學習、理解、練習使用數據和分析技術非常必要,但同樣重要的是建立起對待數據和技術的成熟态度來避免“過度量化”。這樣的态度至少包括以下幾個方面。
首先,設計驅動型研究要求在尚未見到數據之前就思考數據,包括識别任務需要關于什麼單元、時間和維度的數據?如何取得這些數據?這些數據生成過程中可能存在什麼混雜?需要獲得什麼信息以進行糾偏?對于無法排除的混雜因素,我們怎樣估算出混雜帶來的偏差?……總之,對數據的重要思考要基于研究設計而非運行特定統計模型或算法,更不是用便利的數據來“講故事”。
其次,對待數據的成熟态度和方式不僅是關于如何“取” 數據,還包括如何“舍”數據,即根據識别設計對數據進行修剪和舍棄。這聽上去似乎很不“科學”,我們不是總說讓數據說話、要實事求是嗎?這裡的“舍”并不是無視那些不符合我們預設的數據,而是要剔除那些帶來混雜的信息,防止識别偏差。回到GATT/WTO的例子,那些無法進行橫向或縱向比較的“國家—年份”應該被排除在識别之外,因為找不到它們的近似“反事實”導緻其因果效應無法合理地識别。換言之,對于完全找不到現實可比性的“案例”,它們的因果效應無法識别,而要将這些案例包含在分析中就會出現前文所言的“強行識别”問題而帶來偏差和有損信度。這告訴我們,對于特定的識别任務而言,并不是所有的實證信息都是有用的或有益的,不對實證信息進行選擇而将可得數據機械性地納入分析,也是導緻“過度量化”的重要原因之一。
最後,我們也要認識到,複雜、高端、前沿的分析技術并不一定等同于好的識别工具,也不一定會産生更可靠的實證結論。分析技術的選擇要根據識别任務、識别策略和數據情況,并無某種普遍的高低标準。分析技術可以是定性的或定量的,可以是簡單淺顯的統計檢驗或極為複雜高深的算法,但其本身都不是判定社會科學實證研究質量的标準。在這個充滿了技術崇拜的時代,一個很有趣的規律值得特别一提,那就是往往識别策略越精妙,需要使用到的數據分析技術越簡單。例如,在随機實驗或者巧妙地尋找到自然實驗的識别策略下,數據的分析往往極為簡單,根本無須複雜模型和精深算法。社會科學識别充滿了複雜的混雜因素,需要處理複雜的數據生成過程和難以觀測的因素,統計分析技術和算法為此提供強大的工具。我們并不是要反技術,而是不要過度依賴技術而失去對研究的審慎态度和深思熟慮。
結語
以識别為核心的設計驅動型研究追求“勝兵先勝而後求戰”的研究,要避免在缺乏理論關懷和邏輯保障的情況下進行“敗兵先戰而後求勝”,更不要敗而不自知、誤以敗為勝。大數據、算法、人工智能等為社會科學提供了更多的可選信息和技術支持,但卻無法替代研究者所要承擔的核心研究工作。這或許是一個令人喜憂參半的事實:一方面,無法将困難工作交予機器多少令人沮喪;但另一方面,在識别任務上機器無法取代人腦也表明,科學求索仍是人類得到的特别待遇。當數據革命讓行動變得空前容易時,研究者對探索目标和方向的把控也變得空前重要,因為方向的偏差可以讓研究“失之毫厘,謬以千裡”。确立識别革命在社會科學中的地位,建立和平衡它和數據革命之間的雙重運動,對于社會科學的發展具有迫切而深遠的意義。
本文意在強調以識别為核心的設計驅動型研究對大數據時代社會科學發展的特殊重要性,尤其關注在識别革命尚未到達或尚不充分的研究領域中出現的一些重要問題,目的不在于全面系統地介紹設計驅動型研究,也無意于在文中就識别問題提出新穎觀點,文中例子均意在盡量淺顯,僅用以輔助說明。建立和增強識别意識,以及掌握識别策略設計的理念、程序和規範等,需要我們深入和廣泛研讀因果識别教材和相關具體研究,并結合自己的研究進行不斷練習和探索。這是一個漸進的長期積累過程,我們寄希望于通過捷徑來“速成”。從教學和人才培養來看,平衡社會科學中當前的“雙重運動”需要加強識别方面的課程建設,包括關于一般識别和因果識别的原理和方法的系統教學,貫穿于高等教育的各個階段,尤其注意在教學中避免以識别“技術”為中心,而是要透徹講解技術背後的科學原理和認識論邏輯,讓學生知其然也知其所以然。我們有必要讓未來的研究者受到“數據革命”鼓舞的同時也知曉“識别革命”審慎的要義,較早開始建立兩者之間的平衡。
最後我們回顧和總結本文所提及的關于識别革命對實證研究的幾點基本要求:
第一,讓識别對象的定位、定義和表達成為研究工作的重點。這個工作遠遠超過“提一個清晰的‘為什麼’問題”或“有明确的因變量和自變量”的要求。它需要在理論和邏輯上進行嚴密而反複的思考和斟酌,平衡識别對象的細粒度和可行性。進而,無論是使用語言文字還是數學符号,我們都應該在選擇識别技術前将識别對象明确而鄭重地表達出來。
第二,将更多的精力放在識别策略的設計上,包括選擇識别假定、明确什麼是識别任務所需要的實證信息以及如何取得這些信息和使用這些信息等。
第三,最大程度地保證研究的透明度,尤其是對識别假定的陳述和讨論要嚴肅和細緻,包括它們的必要性、合理性、是否過強、在什麼情況下無法成立、在多大程度上影響到識别的結論等。
第四,不過度依賴統計穩健性檢驗。穩健性檢驗幾乎成為傳統定量研究的一個慣性化的操作,而且常常以變換模型設定尤其是将控制變量拿進拿出為主要操作。試想,在精心設計的識别策略下,“控制變量”是那些理論和邏輯告訴我們的混雜因子,不控制它就理應看到識别結果産生變化。如果控制變量随意進進出出而結果依然“穩健”,這正好暴露出研究者對控制變量的選擇缺乏考慮,于提高研究信度并無幫助。模型假定與識别假定是兩套不同的假定,更重要的檢驗是實證發現對于重要識别假定的敏感性分析(sensitivity analysis)。
來源:中國學派公衆号
龐珣:beat365國際關系學系教授




